When using row level indexes there are two types Clustered and NonClustered both of which are there to make data easy to find and sort. Before we look at these index types lets go over a couple of things
- Both these indexes are stored as B-Trees
- Root node is the entry point to the index and each index contains exactly one.
- Leaf Nodes are the destination of the index, exactly what is stored here depends on if it’s a clustered or non clustered index. To get to a leaf node SQL Server starts at the root node and uses the B-Tree structure to find the relevant Leaf Nodes.
- Heap is a table without a clustered index
NonClustered Indexes
Nonclustered indexes work much like an index in a book, The index is stored separate to the actual rows and contains a pointer back to the data (Just like a page number). The leaf node in a nonclustered index contains the fields in the index, any included fields in the index and the key for either the clustered index on the table if there is no clustered index a RowId key to the heap.
Key Lookups
One of the cons of a nonclustered index is if your query is looking at fields that are not in the index you have to do a lookup back to the data once you’ve found your item in the leaf node of the index.
Lets take a look at what this means and how it can affect performance…
If you want to follow along this query will setup a table with some seed data.
DROP TABLE [User]
CREATE TABLE [User]
(
Id INT IDENTITY PRIMARY KEY NONCLUSTERED,
Username NVARCHAR(100),
Firstname NVARCHAR(100),
LastName NVARCHAR(100),
PlaceOfBirth NVARCHAR(100)
)
INSERT INTO [dbo].[User]
(
Username,
FirstName,
LastName
)
VALUES
('clairetemple','Claire','Temple'),
('lukecage','Luke','Cage'),
('jessiejones','Jessie','Jones'),
('tonystark','Tony','Stark'),
('mattmurdock','Matt','Murdock')
DECLARE @LoopCount INT = 1
WHILE @LoopCount < 18
BEGIN
INSERT INTO [dbo].[User](Username,FirstName,LastName)
SELECT
CAST(@LoopCount AS NVARCHAR(4)) + Username,
CAST(@LoopCount AS NVARCHAR(4)) + FirstName,
CAST(@LoopCount AS NVARCHAR(4)) + LastName
FROM [dbo].[User]
SET @LoopCount = @LoopCount +1
ENDYou’ll then have a user table with 655,000 records in it.
Given a username we want to get their first name
SELECT Firstname FROM [User] WHERE [Username] = 'lukecage'If we look at the query plan for this we can see it’s scanning all the rows in the table to look for one with a username of lukecage.
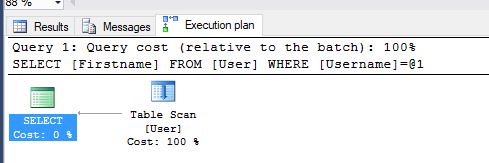
For our small table this is fine but imagine a larger table with millions of records where we are interested in more than a single one, in that case it’s not optimal to have to look at every record to check if the username matches your predicate.
To solve this lets create a nonclustered index on Username so we can search on it without having to look at every record.
CREATE NONCLUSTERED INDEX ndx_user_username ON [dbo].[user](UserName)If we now look at the query plan we can see it’s using our new index and once it’s found the record it’s doing a key lookup back to the heap to get the firstname.
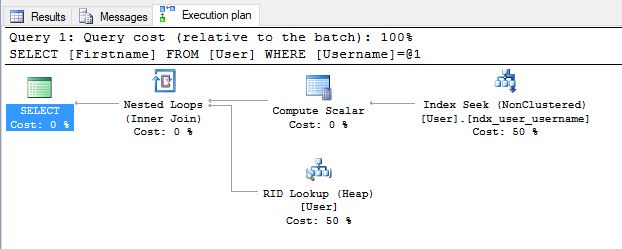
In this case the key lookup is very quick as we’re only selecting one row. If however we were selecting a lot of rows the key lookup can start to become slow as it’s having to constantly jump from the index to the heap.
Let’s imagine we have a slow query, we’ve checked the execution plan/profiled it and it looks like the key lookup is what’s causing the bad performance. What are our options?
- We could add the firstname field to the end of our index
CREATE NONCLUSTERED INDEX ndx_user_username ON [dbo].[user](UserName, Firstname)If we do this then we can see from our plan the key lookup has gone
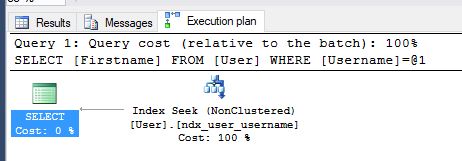
The problem with this approach is we’re not actually wanting to search on firstname and we’ve added the overhead when maintaining the index in that it now has to be stored in Username, Firstname order. This is going to slow down inserts and updates on the firstname field when it doesn’t really need to.
- We could use an include field option added in SQL Server 2005. This is a field that gets stored in the leaf node of the index and doesn’t affect the order of the index, this is perfect when it’s not a field we’re filtering or sorting on.
CREATE NONCLUSTERED INDEX ndx_user_username ON [dbo].[user](UserName) INCLUDE (firstname)You’ll notice the query plan is now the same as above but with the benefit of not having the overhead of maintaining firstname sorting in the index.
Both these techniques are creating what’s called a covering index and that is an index that contains all the information required by your query without the need to go back to the actual table/heap.
Pros
- You can have an unlimited amount of nonclustered indexes on any give table.
- Inserting and Updating data in nonclustered indexes is generally faster than a clustered index as there is less data in the index which can result in less fragmentation on complex indexes.
Cons
- Takes up more space as the index data is stored twice, once in the index and once in the actual table.
- Can have a performance overhead as from the leaf node you need to do a lookup back to the actual table to get any data that is not in the index.
Clustered Indexes
A clustered index doesn’t actually store an index separate to the data instead it defines the order to store the actual data in. This can be a big benefit as the data is stored in the leaf node so you don’t have to do a lookup from the index to the data. The downside is that you can only have one clustered index per table as the tables data is only stored once.
This means any new records inserted into the table need to be stored in order of the index, this can cause a lot of fragmentation for non sequential indexes. If the priority is for high speed inserts it may be better to use a sequential clustered index so data can be quickly appended this is where things like IDENTITY fields can be great.
As you can have only one clustered index and it’s often the fastest way to get data you should think careful about how to use it best.
It’s worth noting that by default SQL Server will create a clustered index automatically on your primary key unless you explicitly tell it not to.
Using the examples from above let’s drop the nonclustered index and create a clustered index on Username
DROP INDEX ndx_user_username ON [dbo].[user]
CREATE CLUSTERED INDEX ndx_user_username ON [dbo].[user](UserName) If we run this with our username query we’ll see that there is no key lookup
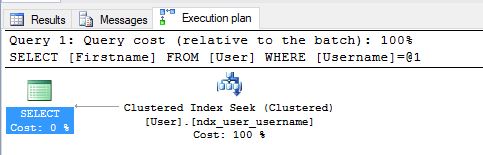
This is because the data is now all stored in username order so we’ve seeked straight to that leaf node and as it’s a clustered index the leaf node will contain the actual data pages of the row rather than a pointer to them.
Pros
- There is no lookup from the leaf of the index back to the table data as the data is stored there.
- Takes less disk space than a nonclustered index as you’re not storing the index data twice.
Cons
- You’re limited to one per table.
- Non sequential clustered indexes an cause a lot of fragmentation when inserting and updating data.