I was recently debugging a slow running SQL instance, when checking the wait stats I noticed a lot of BAD_PAGE_PROCESS waits…
SELECT * FROM sys.dm_os_wait_stats ORDER BY wait_type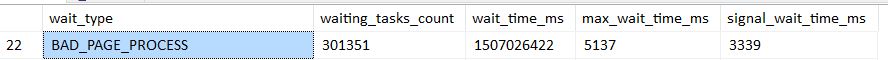
The MSDN description of this wait type is
Occurs when the background suspect page logger is trying to avoid running more than every five seconds. Excessive suspect pages cause the logger to run frequently.
My initial reaction after seeing this was to track down which database had the bad pages using the suspect_pages table in msdb.
SELECT
DB_NAME(database_id) Db,
file_id,
page_id,
event_type,
error_count,
last_update_date
FROM
msdb.dbo.suspect_pagesFrom here we get a list of database with bad pages and an indication of how spread the issue is.

In my case there was a single database with a number of suspect pages. From here if you want to know more you can run the following statement on the database in question…
DBCC CHECKDB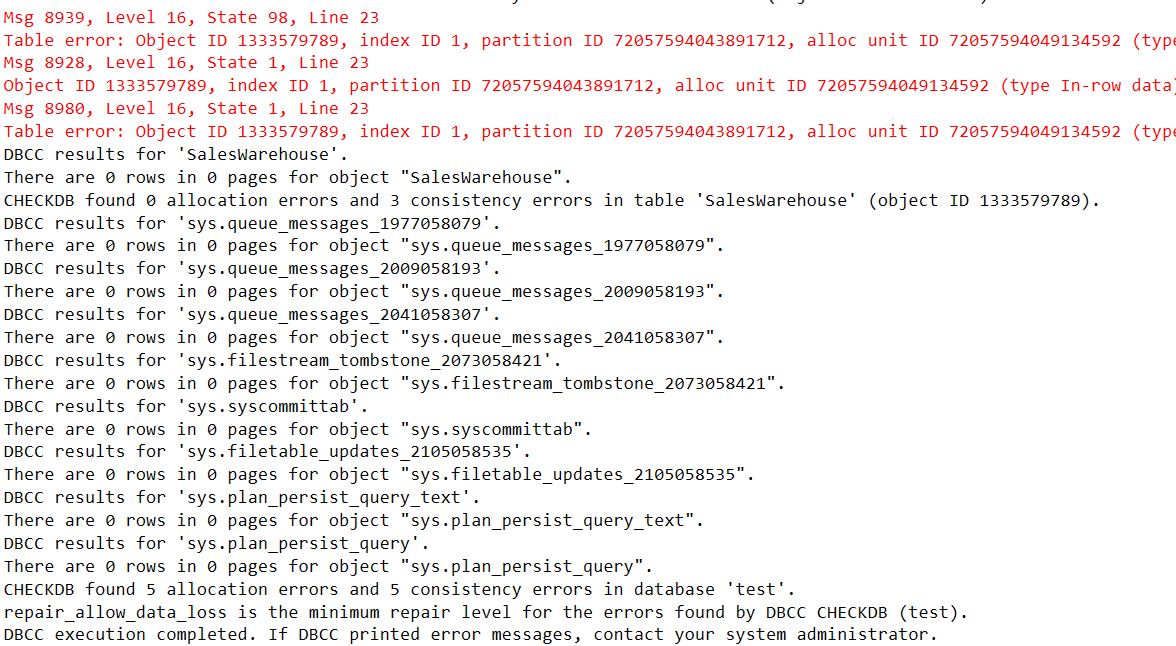
Looking at that error it suggests it may be possible to repair the database using DBCC CHECKDB (dbNName, REPAIR_ALLOW_DATA_LOSS), doing this will involve an unknown amount of data being lost. In my case and I would guess in most cases in this situation the safest thing to do is to restore the most recent backup. After resotring the most recent backup of the database from a couple of hours ago, I ran DBCC CHECKDB and all was good again.

One take away from this is if you have corrupt pages and don’t realise then you could end up backing them up which makes rolling back a lot harder. Depending on your workload and backup schedule it’s almost certainly worth running CheckDB before each backup.