I wanted to document a couple of important tasks you should be doing as part of your SQL Server maintenance/backup strategy to not only recover from corruption with the smallest amount of loss but also be aware of it as soon as possible. If not setup correctly your database could go weeks or even months with undetected corruption at which point do you have backups that even go that far back to recover lost data? Probably not….
Forcing Chaos
Let’s setup a simple test database with a single table….
DROP DATABASE Chaos
CREATE DATABASE Chaos
GO
USE Chaos
GO
CREATE TABLE Blah(Id INT)
CREATE NONCLUSTERED INDEX ndx_blah ON blah(id)
INSERT INTO Blah VALUES(1)Let’s now corrupt one of the pages in the heap by running the following TSQL…
DECLARE @PageToCorrupt INT
SELECT TOP 1
@PageToCorrupt = allocated_page_page_id
FROM
sys.dm_db_database_page_allocations(DB_ID('Chaos'),OBJECT_ID('Blah'),NULL,NULL,'LIMITED') a
WHERE
is_allocated = 1
AND page_free_space_percent IS NOT NULL
AND allocation_unit_type = 1
AND ISNULL(OBJECT_NAME(object_id),'') NOT LIKE 'sysfiles%'
ORDER BY
a.allocated_page_page_id
ALTER DATABASE Chaos SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DBCC WRITEPAGE('Chaos',1,@PageToCorrupt,2000,1,0x67,1)Querying A Corrupt Table
Now lets try reading data from Blah to see what the corruption has done…
SELECT id FROM BlahStill works right? So we now have a corrupted table with no alarms going off. If you look at the query plan for the above select you’ll see why it’s still working…
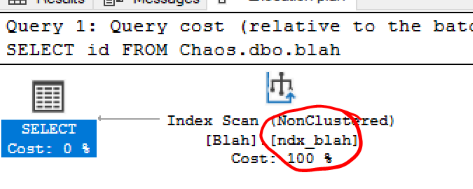
It’s using the index and not the heap we corrupted. If we were drop that index we’d no longer be able to query the corrupted data…
DROP INDEX ndx_blah ON chaos.dbo.blah
SELECT id FROM Chaos.dbo.blah
The key to corruption is knowing about it as early as possible as then you have more options. For example in the above scenario we could have used the data in the index to recreate the table with no data loss.
Let’s try some more examples…
Database Snapshots
Drop the chaos database and recreate it without the index…
DROP DATABASE Chaos
CREATE DATABASE Chaos
GO
USE Chaos
GO
CREATE TABLE Blah(Id INT)
CREATE NONCLUSTERED INDEX ndx_blah ON blah(id)
INSERT INTO Blah VALUES(1)Now lets create a snapshot database and see how it behaves with corrupt data…
CREATE DATABASE ChaosSnapshot ON
(
NAME = Chaos,
FILENAME = 'C:\Temp\ChaosSnapshot.ss'
) AS SNAPSHOT OF ChaosThen run the corrupt script again…
DECLARE @PageToCorrupt INT
SELECT TOP 1
@PageToCorrupt = allocated_page_page_id
FROM
sys.dm_db_database_page_allocations(DB_ID('Chaos'),OBJECT_ID('Blah'),NULL,NULL,'LIMITED') a
WHERE
is_allocated = 1
AND page_free_space_percent IS NOT NULL
AND allocation_unit_type = 1
AND ISNULL(OBJECT_NAME(object_id),'') NOT LIKE 'sysfiles%'
ORDER BY
a.allocated_page_page_id
ALTER DATABASE Chaos SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DBCC WRITEPAGE('Chaos',1,@PageToCorrupt,2000,1,0x67,1)Now lets try querying the snapshot
SELECT * FROM ChaosSnapshot
Boom, the snapshot is reading data from the source database so corrupt source database corrupt snapshot. Let’s just take this a step further and try to restore the Chaos database from the ChaosSnapshot database…
RESTORE DATABASE Chaos FROM DATABASE_SNAPSHOT = 'ChaosSnapshot'Now try selecting database from each database…. Yep we still have 2 corrupt databases. The moral being database snapshots are never going to save your bacon in the event of corruption.
Backups
What do you think happens when you run a backup on a corrupted database? Well it depends on how you take your backup and in what way the database is corrupted. In our example above we’ve deliberately corrupted a page and made it’s checksum incorrect so if we run our backup with checksum turned on it will spot the corruption and error, however if we run it without checksum it’ll produce a backup of a corrupted database with no issue…
BACKUP DATABASE Chaos TO DISK = 'C:\Temp\ChaosAfterCorrupt.bak' /*Will Work Fine*/
BACKUP DATABASE Chaos TO DISK = 'C:\Temp\ChaosAfterCorrupt.bak' WITH CHECKSUM /*Will Error*/Now adding the checksum check to a backup does add overhead so depending on your environment you can decide if you want it here or not, there are other alternatives that we will touch on in the next section. Personally where possible I will always perform database and log backups with checksum then if one ever fails I’m alerted straight away by a failed job alert.
I should note that the corruption we’ve manually forced here makes a bad checksum which causes WITH CHECKSUM to fail however it is perfectly possible for corruption to occur in the buffer before it’s written to disk and then get given a valid checksum masking the corruption. BACKUP WITH CHECKSUM is just one extra layer of defense and should be used in conjunction with CHECKDB and tested restores.
Restores
If you’re not able to run CHECKSUM on your backups for whatever reasons then an alternative is to test restores on another server as soon as the backup has finished. This is also a good place to offload your DBCC CHECKDB which I’ll cover in the next section. A good process for this is after your backup automate the restore to a separate server where you then run DBCC CHECKDB to confirm it’s not corrupt.
You may have seen RESTORE VERIFYONLY used don’t be fooled into thinking this checks the checksums, all this does is check the backup is readable and complete it will not pickup data issues. For example if you made a backup of our corrupt database earlier without the checksum it will have successfully backed up and pass a VERIFYONLY test. You can test this…
RESTORE VERIFYONLY FROM DISK ='C:\Temp\ChaosAfterCorrupt.bak'You’ll see it successfully reads the corrupt backup and reports no issues. Just to note you can also fully restore a corrupt database with no issues…
DROP DATABASE Chaos
RESTORE DATABASE Chaos FROM DISK ='C:\Temp\ChaosAfterCorrupt.bak'Another option you have with restore is the WITH CHECKSUM option much like on flag backups that you can use in conjunction with VERIFYONLY and full restores but they only work if the checksum was created as part of your backup. This means what they’re actually checking is the backup that has already had it’s checksum checked become corrupt on disk since is was created. It looks a bit like this…
RESTORE DATABASE Chaos FROM DISK ='C:\Temp\ChaosAfterCorrupt.bak' WITH CHECKSUM
RESTORE VERIFYONLY FROM DISK ='C:\Temp\ChaosBeforeCorrupt.bak' WITH CHECKSUMDBCC CheckDB
DBCC CHECKDB is one of the more intense maintenance processes you can run on your database but up there with backups is also one of the most important. If your database has any form of corruption hiding in it DBCC CHECKDB will find it. Unfortunately this is one of the most overlooked maintenance tasks in SQL Server and a lot of people don’t run it due to the overhead. It also has some features built in to allow you to trigger repairs which I’m not going to cover here but just know automatic repairs with potential data loss are dangerous things and restoring to an earlier backup is almost always a safer option.
As to how often you should run this it really depends on your RPO and RTO. As I said it’s a heavy process and where possible I run it either in a maintenance window or on a secondary server that I’ve restored a backup to in order to avoid impact to end users. As a rule of thumb I’ll always make sure at the very least this runs once a day. The longer you go without running it the longer you can potentially have corruption getting further and further from the last known good backups.
Let’s look at the syntax in it’s most basic form
DBCC CHECKDB(Chaos) WITH NO_INFOMSGSI normally have this set to run in an overnight SQL Job with alerts set so everyone knows if there are any issues with it. To find out when DBCC CHECKDB was last run without error for a given database you can run…
DBCC DBINFO('Chaos') WITH TABLERESULTSLook for the line with dbi_dbccLastKnownGood and it will tell you the date it last ran without error.
The key with corruption is the sooner you catch it the more options you’re going to have to fix it. It’s all too easy to not put the time in to make sure you’re equipped and alerted for these issues but it’s just going to make the problem a lot worse if it does happen.
Fixing Corruption Issues
The preferred least risky fix is to restore a backup from right before the corruption occurred. If this is too far back or you don’t have a backup you can explore other more risky options….
- If the corruption is in an index you can drop and recreate the index.
- You can run pass repair options into check DB and it will attempt to repair the corrupt. This could involve removing corrupt pages along with the corrupt date from your database.
- Restore a backup to a new database, drop the corrupt object in the primary database and recreate it with database from the restored database. Any data loss here will only be in that one object.
Once you’ve got the database running again you need to investigate what caused the corruption, check for disk/memory errors run tests where possible. Normally depending on the environment I wouldn’t carry on using a disk that’s had corruption on it, it’s rarely a one off and far cheaper to replace the disk or memory.
Summary
In short where possible in your environment do as many of the following as possible
- Verify full backups using WITH CHECKSUM
- Take transaction log backups regularly WITH CHECKSUM
- Test restores of backups to a second server WITH CHECKSUM
- Run DBCC CHECKDB in intervals in accordance with your RPO/RTO