Picture the scene….. DBA Doug is sitting in his cubicle minding his own business when App Dev Allister gives him a call…
Allister : "Hey Doug, got this really slow query can you tell me why?"
Doug : "Sure send me the execution plan"
Allister "One sec.. Requested the plan it's got missing index recommendations, I don't need you now thanks"
Hangs up....
Rinse and repeat the above and overtime the DB gets slower and slower across the board when performing Insert,Update,Delete operations. How could these indexes cause so much trouble if SQL Server recommended them? Surely this is the best practice?
Index recommendations are just that recommendations and in fact I would argue they are not even that, they should be treated as a starting point for investigation and not a right click create index solution. There are a few reasons for this…
- The recommendation often makes no sense to the query in question and actually can give no performance improvement when you test it.
- The recommendation doesn’t look for other similar indexes that might be worth changing rather than adding a new one.
- The recommendation only looks at predicates on where clauses and joins for it’s sort and select fields for it’s includes. Anything in a group by or order by is completely ignored even though you can nearly always get better performance by factoring this into your index design.
Lets look at some examples….
I’m working with the 1gb StackOverflow database that can be downloaded from Brent Ozar Unlimited
Imagine the following query to get all users from the United Kingdom ordered by their name…
SELECT
Id, DisplayName
FROM
Users
WHERE Location = 'United Kingdom'
ORDER BY DisplayNameOn a table with no nonclustered indexes and a single clustered index on ID this is not optimal. If we turn on STATISTICS IO by running this…
SET STATISTICS IO ONThen run the above query again we can see how many reads this query needed…
Table 'Users'. Scan count 5, logical reads 7778, physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Specifically we’re interested in the reads here which at this point were 7778. If We turn on execution plans and run the query again it looks like this…
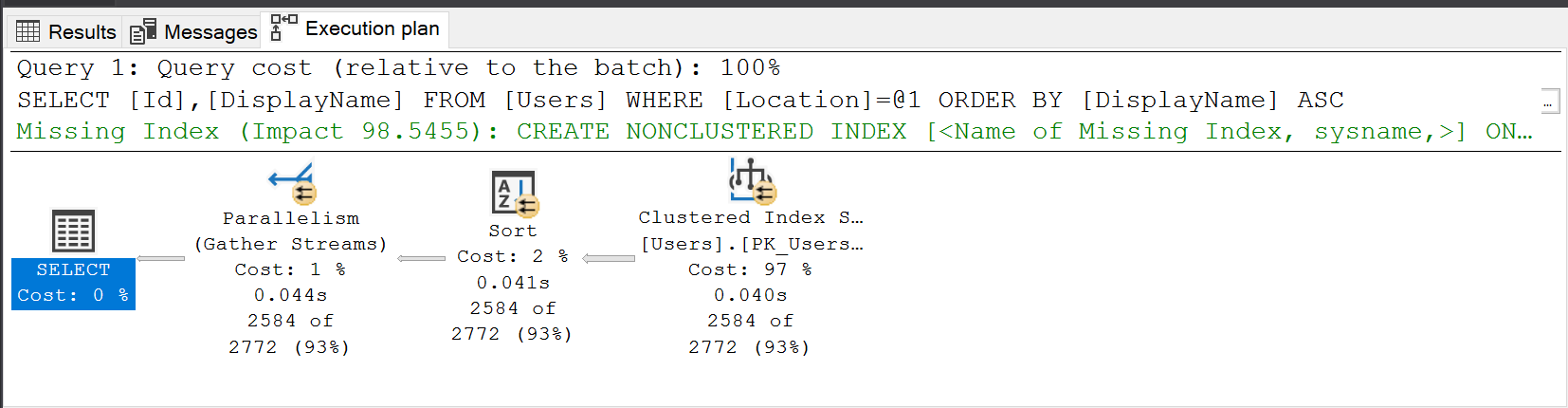
We can see it’s reading all the rows from our clustered index and then sorting them. We can also see there is a recommended missing index! Bingo, Our problems are solved! (Maybe). Let’s create that index….
CREATE NONCLUSTERED INDEX ndx_users_location_include_displayname
ON [dbo].[Users] ([Location])
INCLUDE ([DisplayName])Now let’s run our query again and take another look at the statistics/execution plan…
Table 'Users'. Scan count 1, logical reads 23, physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
So we’ve made a huge improvement to the rows read and this index has massively improved the performance of this query. Also if we look at the execution plan you’ll see we no longer have missing index recommendations..
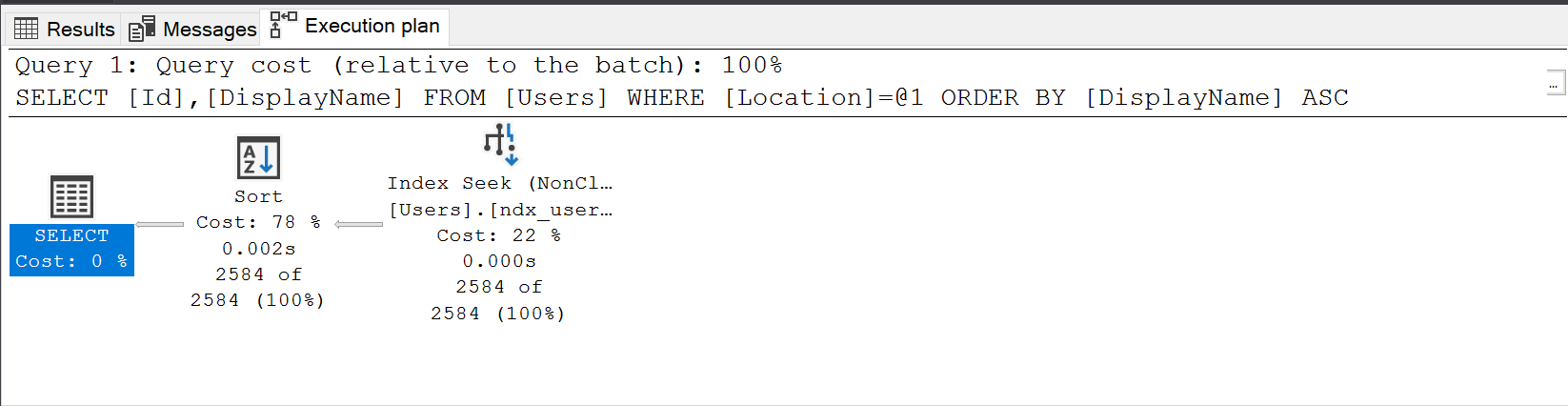
However notice we still have a sort operator in there, these operators can be very costly for CPU in larger queries and a better index for the above query alone would have been…
CREATE NONCLUSTERED INDEX ndx_users_location_displayname
ON [dbo].[Users] (Location, DisplayName)The reads stay the same but if we look at the plan the sort is now gone…
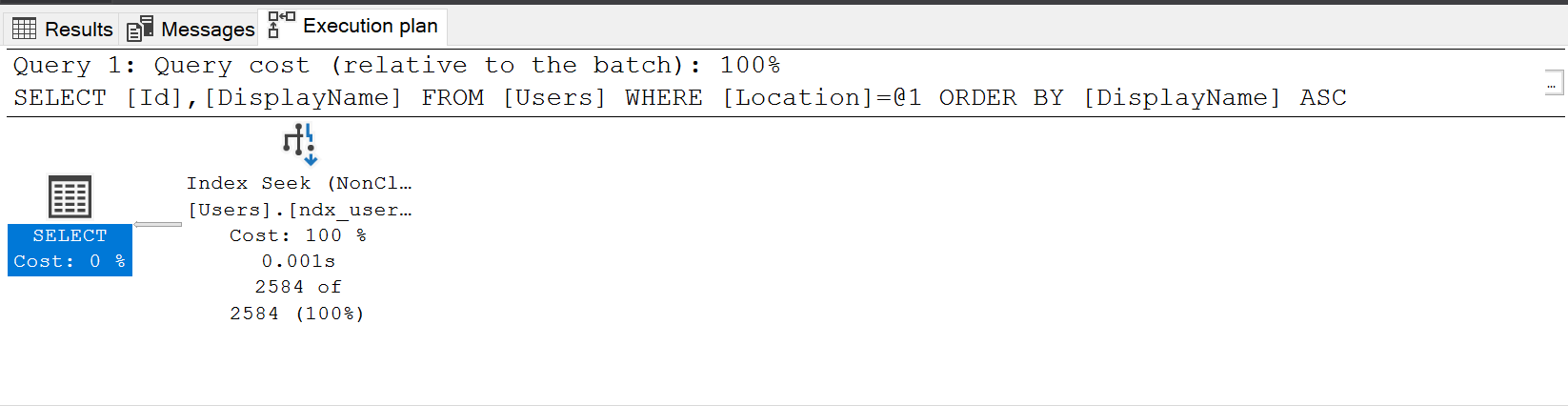
So given what we’ve seen above looking at our query in isolation the missing index recommendation did actually give us a good starting point, however that is all it was and at that point we really need to understand what in the query it’s recommending it for and if it actually makes sense/needs changing.
Now let’s imagine marketing want our query to also pull out age so they can target specific people in their campaigns, simple right?
SELECT
Id, DisplayName, Age
FROM
Users
WHERE Location = 'United Kingdom'
ORDER BY DisplayNameUh Oh our reads have jumped back up and our plan now has a new missing index…
Table 'Users'. Scan count 5, logical reads 7778, physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
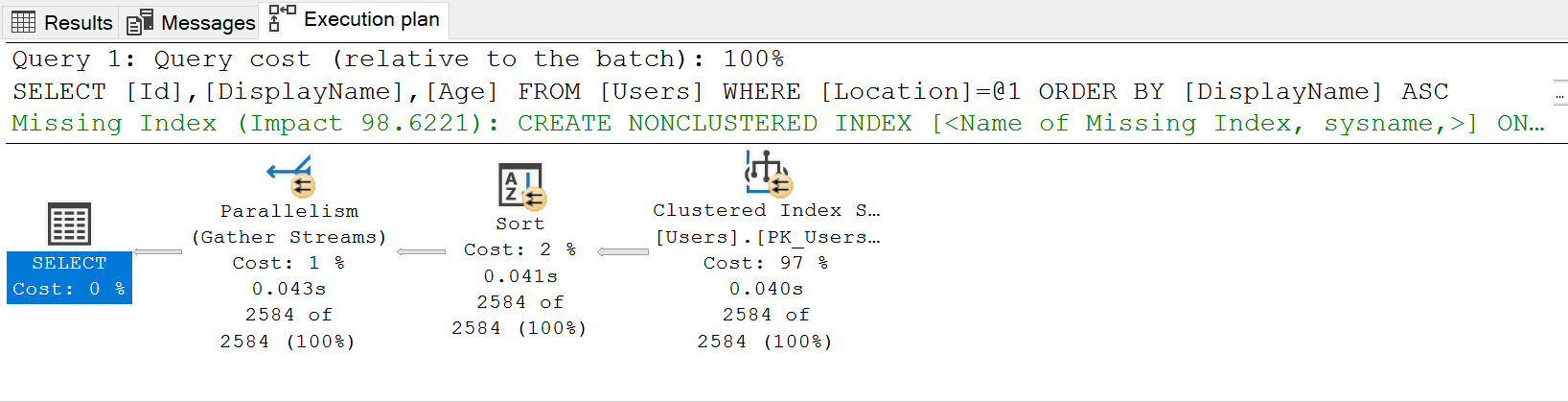
So what index is it recommending?
CREATE NONCLUSTERED INDEX ndx_users_location_include_age_displayname
ON [dbo].[Users] ([Location])
INCLUDE ([Age],[DisplayName])But wait don’t we already have an index that is almost exactly the same as this but without the included age field? Yup! In this situation you will nearly ALWAYS be better off adding Age as an include to the existing index rather than creating a new one. Every index you add has a maintenance overhead, the only gain we get by creating the above index rather than changing our existing one is that if other queries are using the existing index and they don’t need age then they will take a small hit on additional reads as they will now be pulling back age as an include when they may not need it.
What’s dangerous about this is that as queries evolve and you slowly add more fields or remove them you keep creating the recommended indexes and end up in a swamp of un-optimal indexes that you could be paying a big maintenance cost for. SQL Server has not build in support to recommend index removal.
However using the index information in a number of the sys tables you can actually write queries to spot indexes that overlap so you can look at removing them if they don’t make sense. There is a great script from Brent Ozar Unlimited called sp_BlitzIndex which can help wit this.
If we run that script after creating the above overlapping index we can see this…

Using this we can look into similar indexes with a view to possibly removing some. It will also try to give information on how much indexes are used but just be cautious that these values reset under a number of conditions like server restarts and index rebuilds.