Indexing on In Memory OLTP tables is a little different from your traditional on-disk rowstore tables…
In Memory Differences…
- There is no clustered index
- The nonclustered index still exists but its structure is quite different.
- There is a new hash index ideal for unique single record lookups
Below I’m going to go over these points with demos, these demos are all run on a data dump of the Stack Overflow Database from 2010 which can be downloaded from BrentOzar.com. They all revolve around creating the following in memory table and copying the relevant fields out of the Stack Overflow user table to test out different indexing strategies…
CREATE TABLE People
(
Id INT,
Name NVARCHAR(200),
Location NVARCHAR(200),
CONSTRAINT pk_people PRIMARY KEY NONCLUSTERED (id)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY=SCHEMA_AND_DATA) No Clustered Index
In Memory OLTP table indexes are just pointers to the in memory data structure for the row and all its columns, this means that from any item in an index you have full access to all the columns in the row with no lookups needed. This effectively makes a nonclustered index on an in memory table act like a clustered index in that it will be a covering index for any query that uses it.
NonClustered Index
These are quite different on in memory tables to on disk tables.
If you query an on-disk table index the query will via a seek or a scan end up on a leaf node which will contain the fields in the index and an identifier (RID or clustered index key) back to the underlying table for lookups to any additional fields the query needs.
In Memory indexes have eliminated the need for locking due to the way they work, traditional indexes use a B-Tree whereas In Memory indexes are something the SQL Server team coined as BW-Tree, you can read more about BW-Trees in this research paper.
The end result is much the same as the indexes you know and love with classic on-disk nonclustered indexes. One thing to note is that in memory table schema cannot be altered once it is created so and all indexes must be created inline with the table creation. Let’s create our in memory people table with a clustered index on Id (Primary Key) and Location…
CREATE TABLE People
(
Id INT,
Name NVARCHAR(200),
Location NVARCHAR(200),
CONSTRAINT pk_people PRIMARY KEY NONCLUSTERED (id),
INDEX ix_people_location NONCLUSTERED(Location)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY=SCHEMA_AND_DATA) Lets then test our a couple of queries…
SELECT * FROM People WHERE id = 1
Notice anything odd about that plan? Yup, no key lookup. It’s used the index ix_people_location which only has ID on it and no include fields yet we’ve managed to do a SELECT * with no key lookups! Result!
‘Lets look at another query…
SELECT * FROM People WHERE id < 100
Again the exact same plan but this time we’ve returned 100 records with no key lookups, probably not surprising given the previous query but I just wanted to highlight it anyway.
Lastly, let’s look at a query with multiple matches on a single predicate
SELECT * FROM People WHERE Location = 'Brighton'
Basically the same plan again with the only difference we’re now going against the location index.
Now let’s look at something else that does behave quite differently…
SELECT TOP 100 * FROM People ORDER BY Location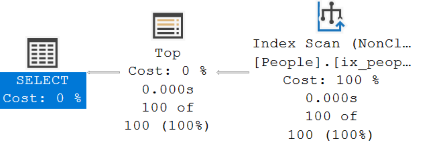
Looks ok right, it’s returned the ordered data using our location index with no sort needed. Well, what happens if we want it descending?
SELECT TOP 100 * FROM People ORDER BY Location DESC
Hmmm, Not Good. It’s performed a manual sort even though we have an index on the field we want sorted, an on disk nonclustered index would have no trouble with this. This is because on disk indexes use a doubly linked list to scan leaf nodes (Allowing 2 way traversal) whereas in memory tables do not. If you need to return data ordered in more than one direction then you need to define multiple indexes to store the data ordered.
New Hash Index
The Nonclustered index works great for finding ranges of records but when the SQL Server team were changing so much with In Memory OLTP they also designed a new type of index to speed up seeks to single unique records, e.g find me the record with id x. It’s actually just what it sounds like, SQL Server will hash the fields in the index and store that hash along with a pointer to the in memory location of the row(s).
Hash indexes perform great when the index is unique or very close to it, if however you start to get lots of records in the index hashing to the same value inserts and seeks and updates can slow down massively and you should think about using a nonclustered index instead.
When you define a hash index you have to tell it how many hash buckets you want, this should be a figure 1-2* the amount of unique values you plan to have in the index. A hash bucket defines how many possible values SQL Server will calculate when hashing your index. For example, if you define a hash bucket count of 10 will only ever give 10 possible hashes even if you store a million different values, in this case each bucket will end up with something like 100K rows which will all need to be scanned when you are seeking a record. Ideally, you want a single record per hash bucket then you can just hash the predicate in your query and go directly to the record. Something to watch out for here is that the values within a hash bucket are stored in order (This makes scans within a bucket faster) so if you under define your bucket count and end up with a many rows in a hash bucket then inserts\updates can take a big hit as once they’ve found the correct hash bucket they need to then scan through it to find the correct place to insert\move new row.
Because hash indexes are really designed for retrieving single rows they do not worry about sorting the data so if you’re doing anything that requires a range of data to be returned a hash index is not a good fit e.g WHERE x > y.
With the above in mind lets try a single record lookup, First, recreate the People table with a hash index on the ID field…
CREATE TABLE People
(
Id INT,
Name NVARCHAR(200),
Location NVARCHAR(200),
CONSTRAINT pk_people PRIMARY KEY
NONCLUSTERED HASH(Id) WITH (BUCKET_COUNT=1000000)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY=SCHEMA_AND_DATA) Now lets run our single record lookup from before…
SELECT * FROM People WHERE id = 1
Pretty much the same query plan as the non clustered version however if we compare the cost of this one it’s gone from 0.0004596 to 0.0000175 so as expected the hash match for single record on a properly sized bucket far outperforms the nonclusterd index.
The End
With the above information, you should be armed with everything you need to create optimized indexes on your in memory tables.