What Are Filtered Indexes
Filtered indexes are essentially an index with a predicate on them filtering the data that gets stored in the index. For example on a bug tracking system I could creatre a filtered index that just indexed bugs with a status of open.
This post will make more sense if you already know what non filtered indexes are and how they work, see SQL Server Clustered & NonClustered Indexes Explained for more information.
When To Use Filtered Indexes
Filtered indexes make sense when you’re querying a small portion of the overall table and are less interested in the rest of it. They allow you to have a smaller index which means you can get to your data faster with less reads. If you get it right based on your data and query needs you’ll reduce the writes required to maintain the index and the reads required for the query to complete. For example imagine a bug tracking system, we’re rarely going to want to query the closed bugs but will frequently query a list of open bugs, we could use a filtered index to only index bugs with a status of open.
Examples
Let’s setup an example bugs table for our bug tracking software with some example statuses
CREATE TABLE dbo.BugStatus
(
Id INT IDENTITY PRIMARY KEY,
[Status] NVARCHAR(20)
)
INSERT INTO dbo.[BugStatus]([Status])
VALUES
('Open'),
('Closed'),
('OnHold'),
('InTest'),
('InProgress')
CREATE TABLE dbo.Bugs
(
Id INT IDENTITY PRIMARY KEY,
Title NVARCHAR(100),
[Description] NVARCHAR(MAX),
BugStatus INT FOREIGN KEY REFERENCES dbo.BugStatus(Id)
)Assuming we’re actually fixing bugs then overtime 99% of bugs will be Closed and for the most part we’re not interested in querying those bugs, in this situation a filtered index on open bugs may be a good idea as that’s the most common dataset to query on and it’s a very small subset of the overall table.
Let’s fake some data to test this on…
DECLARE @InsertCount INT
--Add closed bugs
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
VALUES('Closed Title Blah','My Description',2)
SELECT @InsertCount = 0
WHILE @InsertCount < 20
BEGIN
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
SELECT Title,[Description],BugStatus FROM Bugs WHERE BugStatus = 2
SET @InsertCount = @InsertCount + 1
END
--Add InTest
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
VALUES('In TestTitle Blah','My Description',4)
SELECT @InsertCount = 0
WHILE @InsertCount < 3
BEGIN
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
SELECT Title,[Description],BugStatus FROM Bugs WHERE BugStatus = 4
SET @InsertCount = @InsertCount + 1
END
--Add OnHold
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
VALUES('On Hold Title Blah','My Description',3)
SELECT @InsertCount = 0
WHILE @InsertCount < 5
BEGIN
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
SELECT Title,[Description],BugStatus FROM Bugs WHERE BugStatus = 3
SET @InsertCount = @InsertCount + 1
END
--Add Open
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
VALUES('Open Title Blah','My Description',1)
SELECT @InsertCount = 0
WHILE @InsertCount < 7
BEGIN
INSERT INTO dbo.Bugs(Title,[Description],BugStatus)
SELECT Title,[Description],BugStatus FROM Bugs WHERE BugStatus = 1
SET @InsertCount = @InsertCount + 1
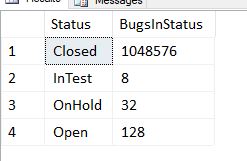
END This gives us a good distribution of statuses to work with…
Let’s assume the home screen of our application lists the last 100 raised bugs that have a status of open…
SELECT TOP 100
Bugs.Id,
Bugs.Title,
Bugs.[Description]
FROM
dbo.Bugs
WHERE
Bugs.BugStatus = 1
ORDER BY id DESCFrom this we’ll get the following execution plan…

We can see we’re doing a clustered index scan to order by id and filter just the open bugs. Obviously this isn’t great as it’s scanning the whole table for Status = 1.
At this point we could create NonClustered index on status for the whole table and that would work fine. However we will then be maintaining an index for 99.9% of the table that we’re never going to use because we’re only interested in open bugs. This is where a filtered index is a good fit…
CREATE NONCLUSTERED INDEX ndx_bugs_bugstatus_open
ON dbo.Bugs(id DESC)
INCLUDE(BugStatus, [Description], Title)
WHERE BugStatus = 1Here we’re creating an index on id for our sort, including all the fields our query uses to avoid any key lookups and then we’re filtering by BugStatus = 1. This means when our query does BugStatus=1 SQL Server will know all the rows in that index satisfy our predicate. The reason we indexed on Id rather than BugStatus is because our filtered index will only contain a single BugStatus of 1 so Id makes more sense as it can help with the sort.
If we run our select query again we can see it’s now using our filtered index…

One thing to note filtered indexes will not be used if your predicate in your query is a parameter as SQL Server wont know up front when it creates the plan if the filtered index will cover any parameter you’re ever going to pass it.