I’ve done a few posts on Clustered and Non-Clustered indexes before, what I’ve not however covered and something that is often not thought about is how SQL Server links the NonClustered and Clustered indexes together for lookups.
In Summary, it works like this…
- If a table has no Clustered index (A Heap) then each record in each Non-Clustered index will store the Row Identifier (RID), this is used as a pointer back to the heap, any data required that is not in the Non-Clustered index will use this pointer to go back to the heap and get the additional fields.
- If a table does have a Clustered index then the Non-Clustered indexes do not use the RID as a pointer, instead they use the fields in the Clustered index as the pointer. This is a little surprising to learn at first as for this to work it means that every Non-Clustered index also has the Clustered index fields included in it for it to be able to perform lookups back to the Clustered index.
Lets demo the above points with a quick sample…
CREATE TABLE NonClusteredOnly
(
Id INT IDENTITY,
Name NVARCHAR(100),
INDEX ndx_nonclusteredonly_name NONCLUSTERED(Name)
)
CREATE TABLE ClusteredOnly
(
Id INT IDENTITY PRIMARY KEY,
Name NVARCHAR(100)
)
CREATE TABLE ClusteredAndNonClustered
(
Id INT IDENTITY PRIMARY KEY,
Name NVARCHAR(100),
INDEX ndx_clusteredandnonclustered_name NONCLUSTERED(Name)
)
INSERT INTO NonClusteredOnly (Name)
SELECT specific_name
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'
INSERT INTO ClusteredOnly (Name)
SELECT specific_name
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'
INSERT INTO ClusteredAndNonClustered (Name)
SELECT specific_name
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'After running that you’ll have 3 tables and about 500 records in each (Will vary depending on which version of SQL Server you’re running).
Let’s first look at what happens if we filter on the name column and return both ID and Name from ClusteredOnly…
SELECT id,[Name] FROM ClusteredOnly
WHERE [Name] LIKE 'sp_verify_job%'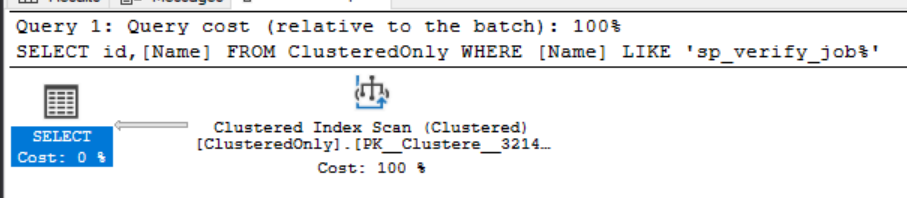
As you probably expected we have no index that can help with our predicate so it does a full scan on the Clustered index.
Now let’s run that same query on our table with only a single Non-Clustered index…
SELECT id,[Name] FROM NonClusteredOnly
WHERE [Name] LIKE 'sp_verify_job%'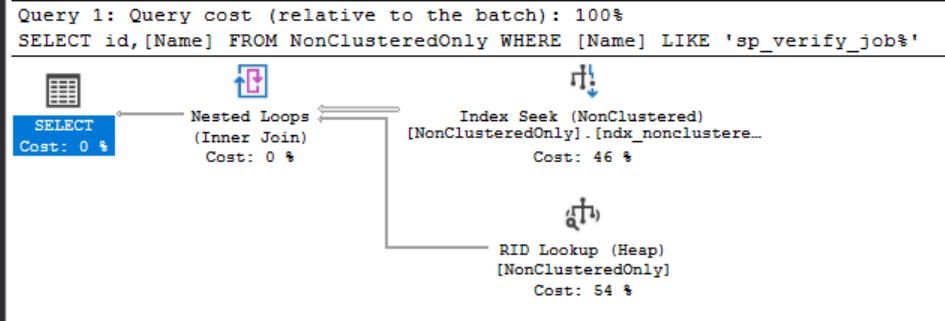
In this case, we’re using the Non-Clustered index to seek on our predicate but because that index doesn’t have ID in it and our query wants the ID field it then uses the RID (Record Identifier) to go back to the heap and get that data in that field.
It gets more interesting when we run that same query on our table with a Clustered index on ID and Non-Clustered on Name, the obvious thing you’d expect to see is probably seek on the Non-Clustered then a lookup to the Clustered index to get the ID field, However…
SELECT id,[Name] FROM ClusteredAndNonClustered
WHERE [Name] LIKE 'sp_verify_job%'
You can see here we’ve got both ID and Name from the Non-Clustered index even though it only has name in it. This is possible because as I mentioned above all Non-Clustered indexes include the Clustered index columns in them as a way to point back to the Clustered index, in this case we’re not referencing anything that’s not either in the Non-Clustered or Clustered index so no lookup is needed.
Now that we’ve demonstrated that each record has a pointer back to the Clustered index and that pointer is the fields in the Clustered index you may now be wondering how that works if the Clustered Index is not unique?
Let’s setup another test to demo this…
CREATE TABLE NonUniqueClusteredAndNonClustered
(
ID INT,
[Name] NVARCHAR(100),
[LookupText] NVARCHAR(100),
INDEX ndx_clustered CLUSTERED (Id),
INDEX ndx_nonclustered NONCLUSTERED(Name)
)
INSERT INTO NonUniqueClusteredAndNonClustered (Id,Name,LookupText)
SELECT 1,specific_name,'Test'
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'We now have our Clustered index on ID and every single value in that field is 1, we also have a new field LookupText that is not included in any index. Knowing what we’ve covered above we know in order to get LookupText from a seek on the Non-Clustered index we’d need to use the Clustered index keys to perform a lookup on the Clustered Index to the record in question, But… This can’t work when the pointer is not unique can it?…
SELECT id,[Name],LookupText FROM NonUniqueClusteredAndNonClustered
WHERE [Name] LIKE 'sp_verify_job%'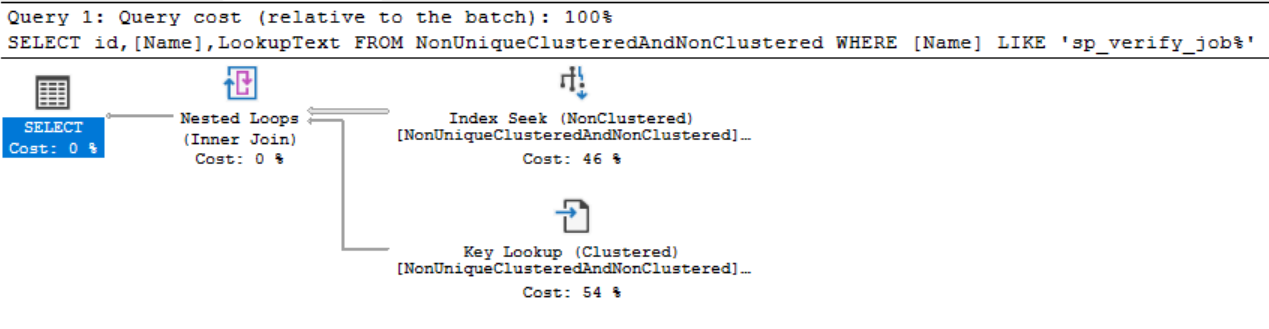
How can it be possible perform a lookup from the Non-Clustered to the Clustered when we have no unique pointer? e.g the pointer is 1 for every single record. Well in this case SQL Server see’s the key is not unique and at the point where it inserts the data is appends a unique 4 byte value to the Clustered Index for each row allowing for the pointer to work. You will never actually see this unique key as it is only used behind the scenes for SQL Server to do things like facilitate these lookups.
Summary
Some things to take away from this…
- You don’t need to include Clustered index fields in your Non-Clustered indexes as they are already there.
- You don’t need to add additional indexes to avoid lookups from Non-Clustered to Clustered when the lookup fields are already defined on the Clustered Index.
- Lookups will never happen from a Non-Clustered index to a field defined on the Clustered Index.
- This can also work in reverse, for any record in a Clustered index you can find the matching record in each Non-Clustered index. This is how things like Deletes and Updates work, e.g Update Clustered Index then lookup each matching record in Non-Clustered indexes and update them too.